原理
当我们发出一个get请求的时候,http server大概发生了下面几个步骤:
- 接受客户端请求
- 接受请求报文
- 处理请求
- 对资源的映射和访问
- 构建响应
- 发送响应
- 记录日志
这一切看来非常像游戏中一条协议的处理,下面详细讲这几个
请求
http的请求的本质是tcp,自然会先建立tcp连接,那么server会在接受连接后,等待报文的到达。
报文
解析报文的过程:
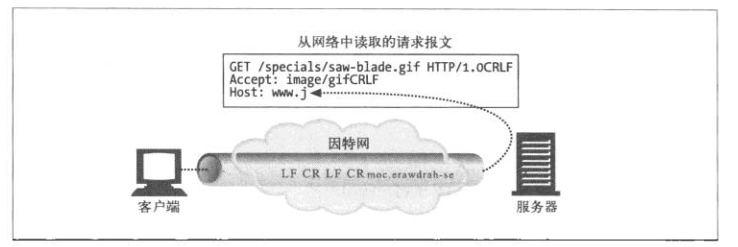
由图可知,当数据没有接受完是不能进行解析报文的。 每行的CRLF和Content-length就是用来判断是否接受完
处理
在解析报文后,就知道浏览器想让server干嘛了,就可以对应做出各种响应。
(GET、POST、PUT、Delete、HEAD、Options)
响应报文
通常包括:(主要还是看协议)
- Content-Type描述了是哪个MIME类型
- Content-Length
- 主体内容
MIME的类型
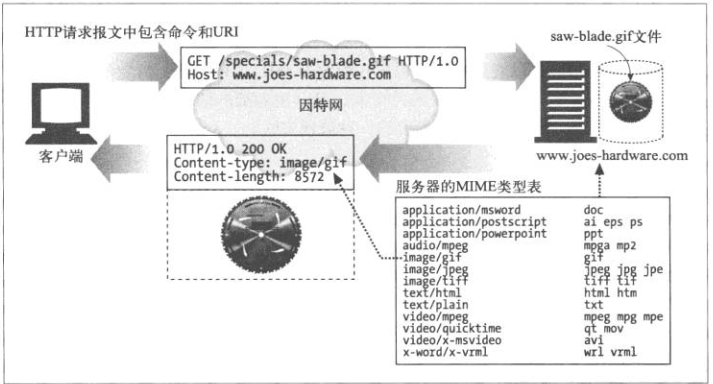
不过也有可能是重定向的响应,响应码为3XX,不是最终的响应
发送
server在发送完报文后,会关闭非持久的连接,对于持久连接是不会关闭的。
echo server
文中有个perl的echo server,这里用python重现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import socket
import traceback
def star_server():
s_socket = socket.socket()
s_socket.bind(("127.0.0.1", 80))
s_socket.listen(5)
print "echo server at 80"
conn, address = None, None
while not conn:
conn, address = s_socket.accept()
recv_chunk = conn.recv(1024)
recv_data = recv_chunk
print "------------------------------"
print recv_data
print "from", address
print "------------------------------"
path = recv_data.split()[1]
if path == "/":
echo_content = raw_input("echo:\n")
try:
response = "HTTP/1.1 200 OK\r\nConnection:close\r\nContent-type:text-plain\r\n\r\n"
response = response + echo_content
conn.sendall(bytes(response))
except Exception, e:
traceback.print_exc()
conn.close()
conn, address = None, None
star_server()
|


评论加载中